
With the MosaicBERT architecture + training recipe, you can now pretrain a competitive BERT-Base model from scratch on the MosaicML platform for $20. We’ve released the pretraining and finetuning code, as well as the pretrained weights.
Give our Github Repo a star here!
Download the MosaicBERT pretrained weights on the Hugging Face Hub!
BERT models—used for everything from sentiment analysis to text summarization—have been the workhorse of modern natural language processing (NLP) since their introduction in 2018. BERT-based models are typically trained in two stages: an initial, self-supervised pretraining phase that builds general representations of language and a subsequent, supervised finetuning phase that uses those representations to address a specific problem.
The pretraining stage for BERT models has historically been computationally expensive; in the original BERT study, for example, the authors trained their models for 4 full days on 16 Google TPUs. One widely cited paper from 2021 pinned the price of pretraining BERT-Large to baseline accuracy at $300-$400 [Izsak et al. 2021]. While there have been many hardware and algorithmic advances since the original BERT study, a majority of respondents in a recent Twitter poll thought training a BERT model was still >$500!.
In this blog, we introduce our optimized MosaicBERT architecture and show how you can pretrain a high-quality BERT model from scratch on the MosaicML platform for $20. We hope this will lead researchers and engineers to feel confident pretraining their own models on domain-specific data, not just fine-tuning existing generic models.
Why Train a BERT Model from Scratch?
We built MosaicBERT to enable ML researchers to pretrain custom BERT models from scratch on their own data. With MosaicBERT, you can build better models for your specific domains without time and cost restrictions.
Once the price is right, the case for training your own BERT model is simple:
- Your domain-specific model can be more powerful: A sizable amount of research has shown that a BERT-style model pretrained from start to finish on a specific domain is more accurate than a BERT model that has been pretrained on generic data and then finetuned on a specific domain. Domain-specific pretrained models have advanced the state of the art in many fields, including biomedicine, materials science, and financial communications (see the appendix for a more extensive list).
- Your proprietary data and models are your competitive advantage: A model pretrained on specific domains gives your business a competitive advantage over others building on generic datasets like Wikipedia entries. One of our financial services customers was able to boost accuracy from 70% to 95% by focusing on their unique domain data.
- You can use your own custom vocabulary and tokenizer for your specific domain. A tokenizer splits text into individual “chunks” to be processed by the NLP model. The size and quality of the tokenized vocabulary directly affect both training efficiency and model accuracy. For example, the drug “acetyltransferase” is tokenized by the standard BERT tokenizer into the seven tokens ace, ##ty, ##lt, ##ran, ##sf, ##eras, ##e instead of one or two tokens reflecting the structure and meaning of the term in a biological context [Gu et al. 2020]. Not only is this tokenization inefficient, but it leads to a suboptimal embedding for biology-related texts that cannot generalize to other related words that incorporate “acetyl” (such as acetylcholine) or “transferase” (such as methyltransferase). Another application of custom tokenization is mathematics, where poor tokenization of numbers (e.g., tokenizing “2023” into the tokens 20 and 23) may limit arithmetic reasoning in language models [Wallace et al. 2019]. By pretraining your own BERT, you can customize the tokenizer to suit your domain and task.
Ready to train your own BERT Model from scratch? Sign up for a demo to see how easy it is to train BERT models (and more!) on our platform.
If you’re an ML researcher or engineer, you may be wondering, “How did we get here?” Read on!
MosaicBERT: 79.6 Average GLUE Score in 1.13 hours on 8 A100s
So how does MosaicBERT perform? MosaicBERT-Base matched the original BERT’s average GLUE score of 79.6 in 1.13 hours on 8xA100-80GB GPUs. Assuming MosaicML’s pricing of roughly $2.50 per A100-80GB hour, pretraining MosaicBERT-Base to this accuracy costs $22. On 8xA100-40GB, this takes 1.28 hours and costs roughly $20 at $2.00 per GPU hour.
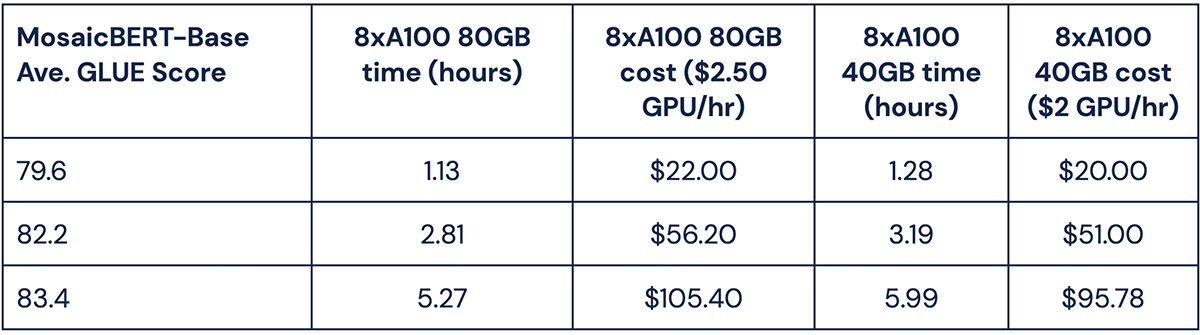
In our benchmarking work at MosaicML, we have found accuracy vs. training time tradeoff curves (i.e. Pareto frontiers) to be the most useful way to benchmark the efficiency and quality of models. For more on how and why we plot tradeoff curves instead of simply reporting single values in tables, see our Methodology blog post.
The Pareto frontiers of average GLUE scores allow us to compare the best possible performance of the two models given different training durations. As can be seen from these plots, MosaicBERT-Base consistently achieves higher accuracy more quickly than the standard BERT-Base across all training durations.
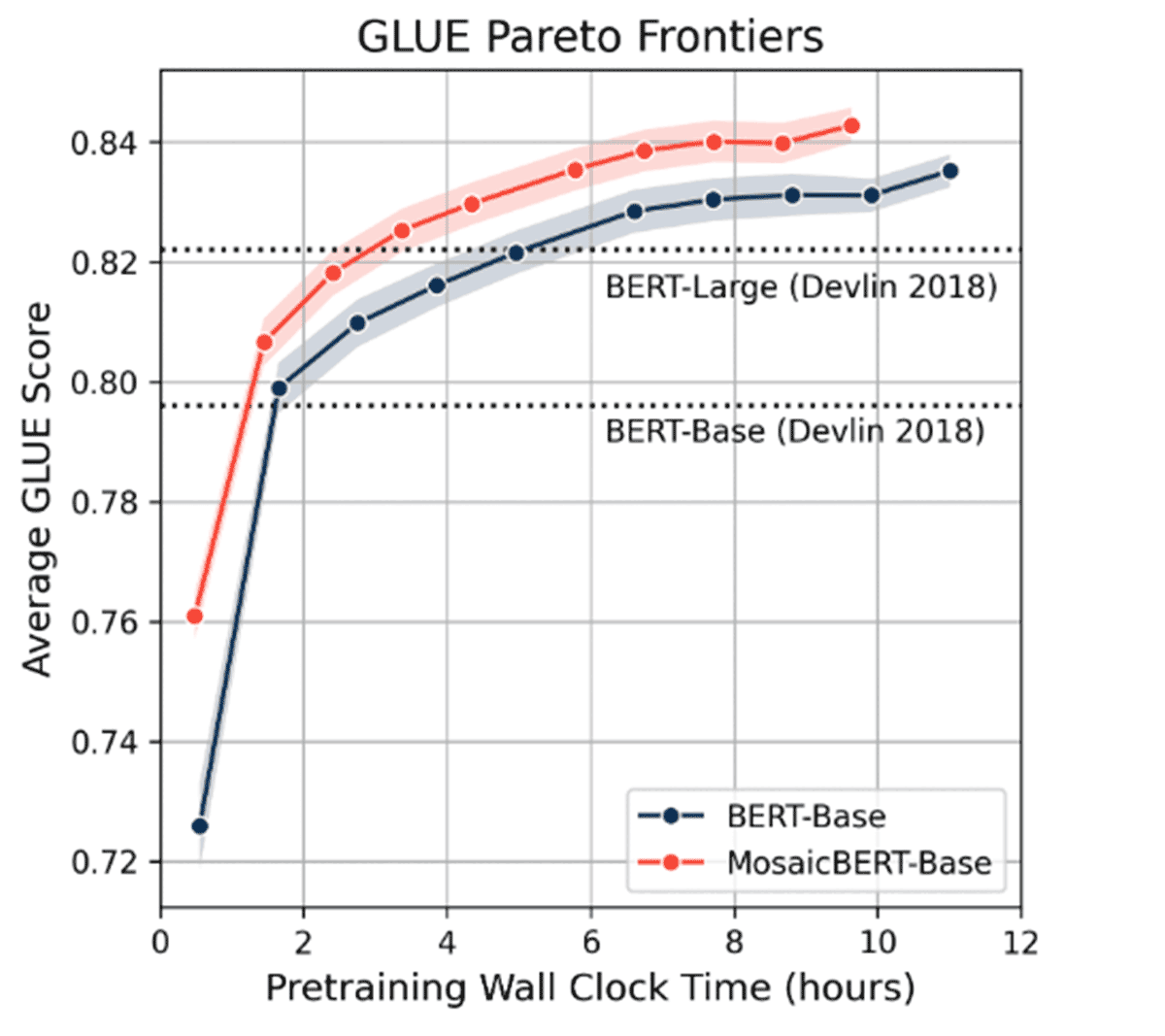
BERT-Base reached an average GLUE score of 79.6 in the original paper, while BERT-Large reached 82.2 [Devlin et al. 2018]. More recent studies that have focused on efficient, low-cost BERT pretraining reached lower baselines for BERT-Base and BERT-Large [Izsak et al. 2021, Geiping and Goldstein 2022]. We include average GLUE scores from these studies in the table below.
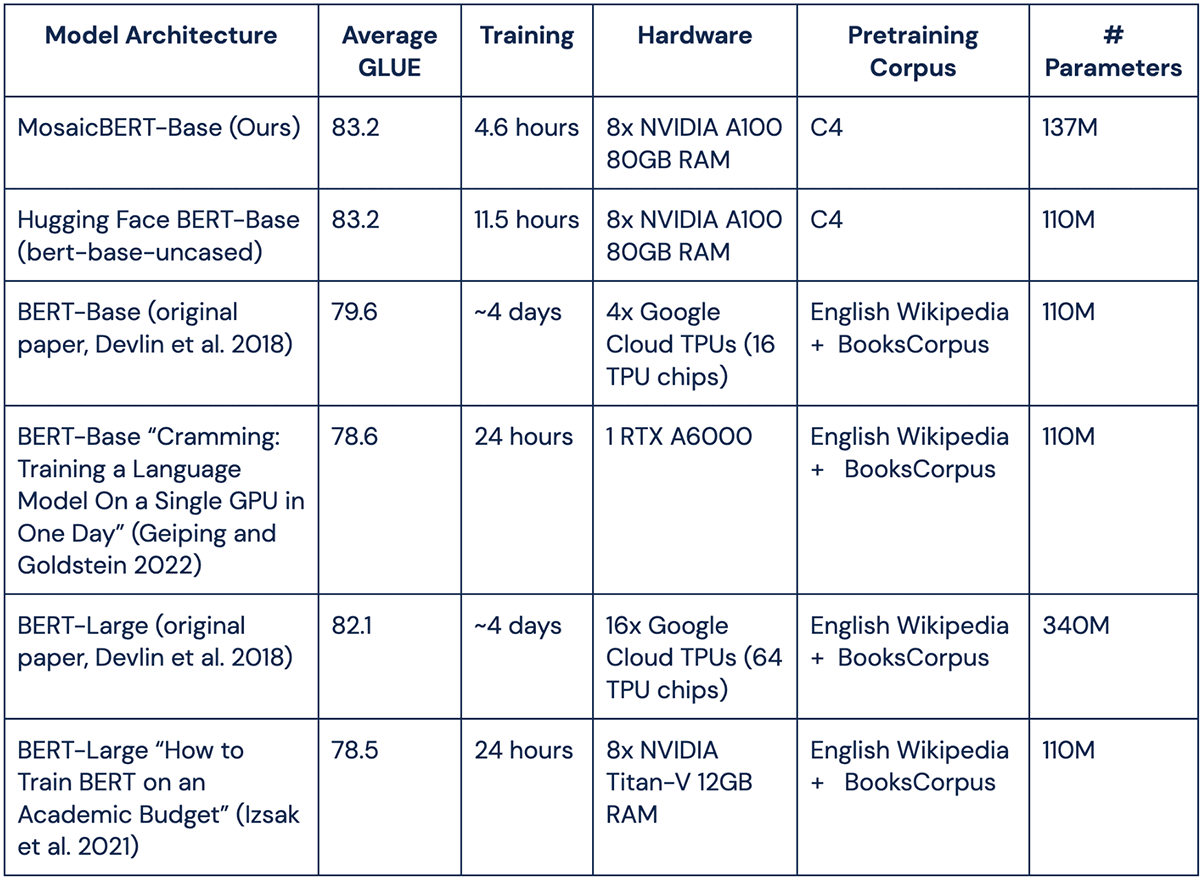
Benchmarking MosaicBERT
We constructed a new, efficient “MosaicBERT” model based on the recent transformer literature and pretrained it from scratch with an improved training recipe. We began with Hugging Face’s bert-base-uncased as a baseline, and then selected GLUE as an evaluation framework and compared our MosaicBERT model to the baseline BERT on standard cloud instances.
Benchmarking against Hugging Face’s BERT-Base
BERT is not just one model but a class of bidirectional encoder transformer models; well-known examples of particular architectures and training configurations include RoBERTa and distilBERT. We chose to benchmark our MosaicBERT against Hugging Face’s bert-base-uncased architecture because it is one of the most popular Hugging Face models (with over 48 million downloads in the past month). This BERT-Base architecture consists of 12 repeated encoder blocks, each with 12 attention heads, and contains a total of 110 million trainable parameters.
Pretraining Configurations with C4
We pretrained the models using BERT’s standard Masked Language Modeling (MLM) objective: the model is given a sequence of text with some tokens hidden, and it has to predict these masked tokens. We pretrained both MosaicBERT and our baseline BERT on the English “Colossal, Cleaned, Common Crawl” C4 dataset, which contains roughly 365 million curated text documents scraped from the internet (equivalent to 156 Billion tokens). We used this more modern dataset in place of traditional BERT pretraining corpora like English Wikipedia and BooksCorpus.
GLUE as a Finetuning Benchmark
One classic benchmark for evaluating the transferability of pretrained language models is GLUE (General Language Understanding Evaluation), which is a combination of 8 different natural language understanding benchmarks. Each task includes a training set (used for finetuning the pretrained BERT model) and an evaluation set (for measuring the final performance of the model on that task). The average of the final scores on the GLUE tasks gives a single number that is indicative of model quality.
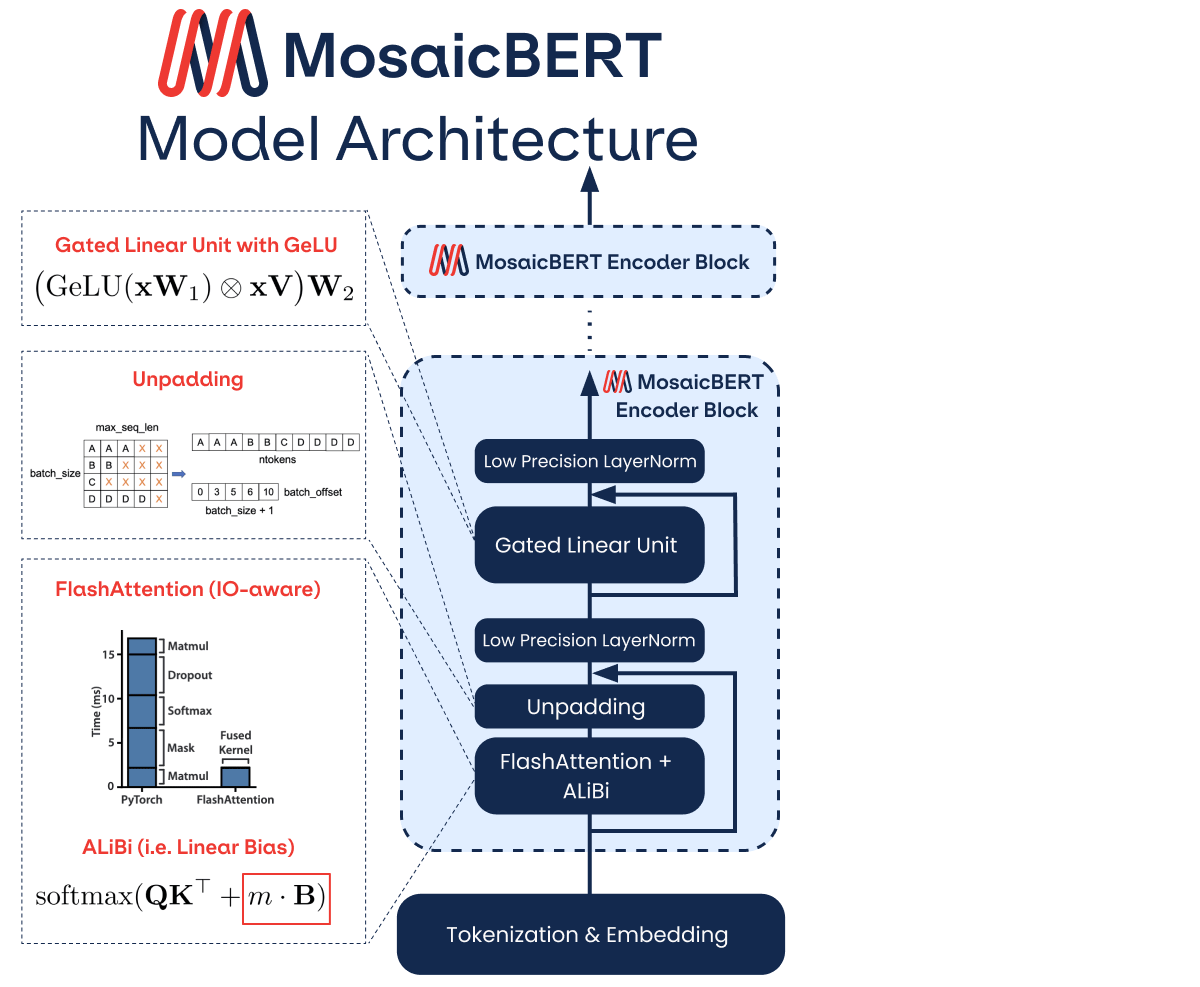
The MosaicBERT Architecture
In order to build MosaicBERT, we adopted architectural choices from the recent transformer literature. These include FlashAttention [Dao et al. 2022], ALiBi [Press et al. 2021], training in an unpadded manner, low precision LayerNorm, and Gated Linear Units [Dauphin et al. 2016, Shazeer 2020]. Some of the architecture optimizations below were informed by our BERT results for the MLPerf v2.1 speed benchmark.
The basic transformer block used in BERT models consists of (1) the attention mechanism and (2) the feed forward layers. In addition, LayerNorm operations are always included. This basic transformer block is then repeated depending on the model size; BERT-Base has 12 repeated transformer blocks. While MosaicBERT stays true to this general structure, our modifications affected both the attention mechanism and the feedforward layers.
1. Modifications to the Attention Mechanism
FlashAttention: Attention layers are core components of the transformer architecture. The recently proposed FlashAttention layer reduces the number of read/write operations between the GPU HBM (high bandwidth memory, i.e. long-term memory) and the GPU SRAM (i.e. short-term memory) [Dao et al. 2022]. We used the FlashAttention module built by hazy research with OpenAI’s triton library.
Attention with Linear Biases (ALiBi): In most BERT models, the positions of tokens in a sequence are encoded with a position embedding layer; this embedding allows subsequent layers to keep track of the order of tokens in a sequence. ALiBi eliminates position embeddings and instead conveys this information using a bias matrix in the attention operation. It modifies the attention mechanism such that nearby tokens strongly attend to one another [Press et al. 2021]. In addition to improving the performance of the final model, ALiBi helps the model to handle sequences longer than it saw during training. Details on our ALiBi implementation can be found here.
Unpadding: Standard NLP practice is to combine text sequences of different lengths into a batch, and pad the sequences with empty tokens so that all sequence lengths are the same. During training, however, this can lead to many superfluous operations on those padding tokens. In MosaicBERT, we take a different approach: we concatenate all the examples in a minibatch into a single sequence of batch size 1. Results from NVIDIA and others have shown that this approach leads to speed improvements during training, since operations are not performed on padding tokens (for example: Zeng et al. 2022). Details on our “unpadding” implementation can be found here.
Low Precision LayerNorm: this small tweak forces LayerNorm modules to run in float16 or bfloat16 precision instead of float32, improving utilization. Our implementation can be found here.
2. Modifications to the Feedforward Layers
Gated Linear Units (GLU): We used Gated Linear Units for the feedforward sublayer of a transformer. GLUs were first proposed in 2016 [Dauphin et al. 2016], and incorporate an extra learnable matrix that “gates” the outputs of the feedforward layer. More recent work has shown that GLUs can improve performance quality in transformers [Shazeer, 2020, Narang et al. 2021]. We used the GeLU activation function with GLU (this is sometimes referred to as GeGLU). The GeLU (Gaussian-error Linear Unit) function is a smooth, fully differentiable approximation to ReLU; we found that this led to a nominal improvement over ReLU. More details on our implementation of GLU are here.
The extra gating matrix in a GLU model potentially adds additional parameters to a model; we chose to augment our BERT-Base model with additional parameters due to GLU modules, as it leads to a Pareto improvement across all timescales (which is not true of all larger models such as BERT-Large). While BERT-Base has 110 million parameters, MosaicBERT-Base has 137 million parameters. Note that MosaicBERT-Base trains faster than BERT-Base despite having more parameters.
Pretraining Optimizations
MosaicML Streaming Dataset
As part of our efficiency pipeline, we converted the C4 dataset to MosaicML’s StreamingDataset format and used this for both MosaicBERT-Base and the baseline BERT-Base. For all BERT-Base models, we chose the training duration to be 286,720,000 samples of sequence length 128; this covers 78.6% of C4.
Higher Masking Ratio for the Masked Language Modeling Objective
We used the standard Masked Language Modeling (MLM) pretraining objective. While the original BERT paper also included a Next Sentence Prediction (NSP) task in the pretraining objective, subsequent papers have shown this to be unnecessary [Liu et al. 2019]. For Hugging Face BERT-Base, we used the standard 15% masking ratio. However, we found that a 30% masking ratio led to slight accuracy improvements in both pretraining MLM and downstream GLUE performance. We therefore included this simple change as part of our MosaicBERT training recipe. Recent studies have also found that this simple change can lead to downstream improvements [Wettig et al. 2022].
Bfloat16 Precision
We use bf16 (bfloat16) mixed precision training for all the models, where a matrix multiplication layer uses bf16 for the multiplication and 32-bit IEEE floating point for gradient accumulation. We found this to be more stable than using float16 mixed precision.
Vocab Size as a Multiple of 64
We increased the vocab size to be a multiple of 8 as well as 64 (i.e. from 30,522 to 30,528). This small constraint is something of a magic trick among ML practitioners, and leads to a throughput speedup.
Hyperparameters
For all models, we use Decoupled AdamW with Beta1=0.9 and Beta2=0.98, and a weight decay value of 1.0e-5. The learning rate schedule begins with a warmup to a maximum learning rate of 5.0e-4 followed by a linear decay to zero. Warmup lasted for 6% of the full training duration. Global batch size was set to 4096, and microbatch size was 128; since global batch size was 4096, full pretraining consisted of 70,000 batches. We set the maximum sequence length during pretraining to 128, and we used the standard embedding dimension of 768. These hyperparameters were the same for MosaicBERT-Base and the baseline BERT-Base.
For the baseline BERT, we applied the standard 0.1 dropout to both the attention and feedforward layers of the transformer block. For MosaicBERT, however, we applied 0.1 dropout to the feedforward layers but no dropout to the FlashAttention module, as this was not possible with the OpenAI triton implementation.
Full configuration details for pretraining Hugging Face BERT-Base and MosaicBERT-Base can be found in the configuration YAMLs here.
Finetuning Performance on the GLUE Tasks
MosaicBERT-Base outperforms BERT-Base in four out of eight GLUE tasks across pretraining durations. The baseline Hugging Face BERT-Base reached an average GLUE score of 83.2% in 11.5 hours (A100-80GB), while MosaicBERT reached the same accuracy in roughly 4.6 hours on the same hardware, which is roughly a 2.38x speedup.
The quality of MosaicBERT on individual GLUE finetuning tasks can be seen in the plots below. Accuracy vs. wall clock time tradeoff curves compare performance for different pretraining durations.
The space of NLP benchmarks and tasks has exploded in recent years; in case you’ve forgotten the finer details of GLUE, we include more information on the individual tasks at the end of this blog.
MNLI, QNLI and QQP are the largest datasets in the GLUE benchmark, with 100k-400k training examples. MosaicBERT-Base is strictly Pareto-optimal for these tasks relative to BERT-Base. We interpret this to mean that the architectural changes and training recipe we chose resulted in an optimized, efficient BERT-Base model.
The quality of both models on smaller datasets (3k-67k training samples) is much more variable, as shown by the large error bars (standard deviation across n=5 pretraining seeds) for SST-2, MRPC and STSB. Regardless of this variation, MosaicBERT-Base performs equivalently to BERT-Base on these tasks across training duration.
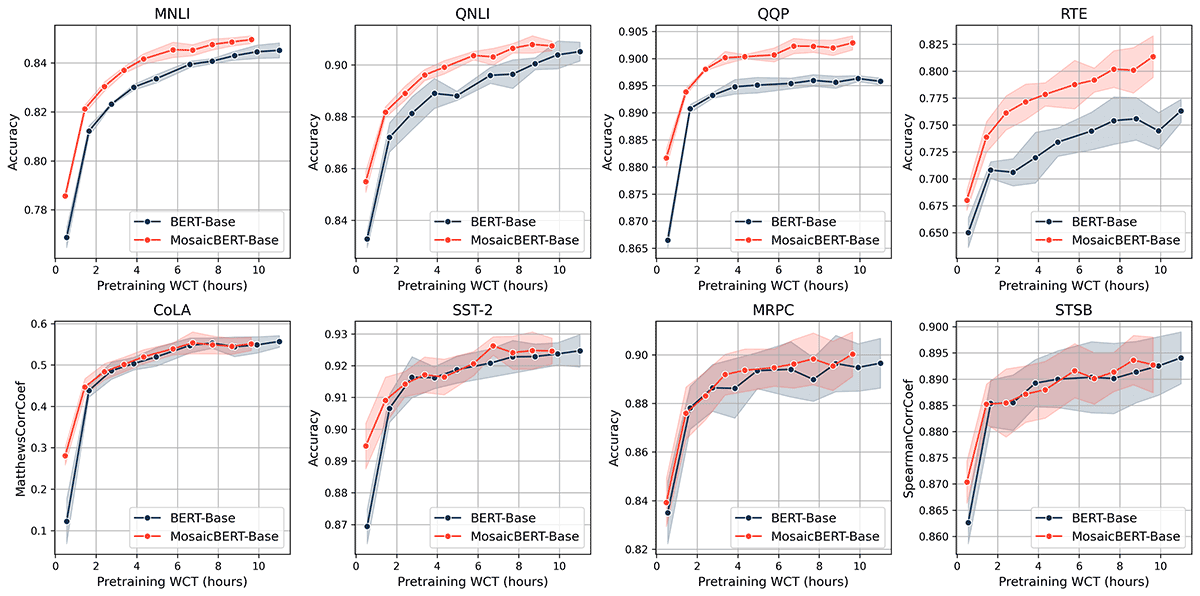
At the start of our experiments, we used the baseline model to find a good set of GLUE hyperparameters and kept them fixed throughout, including when finetuning MosaicBERT.
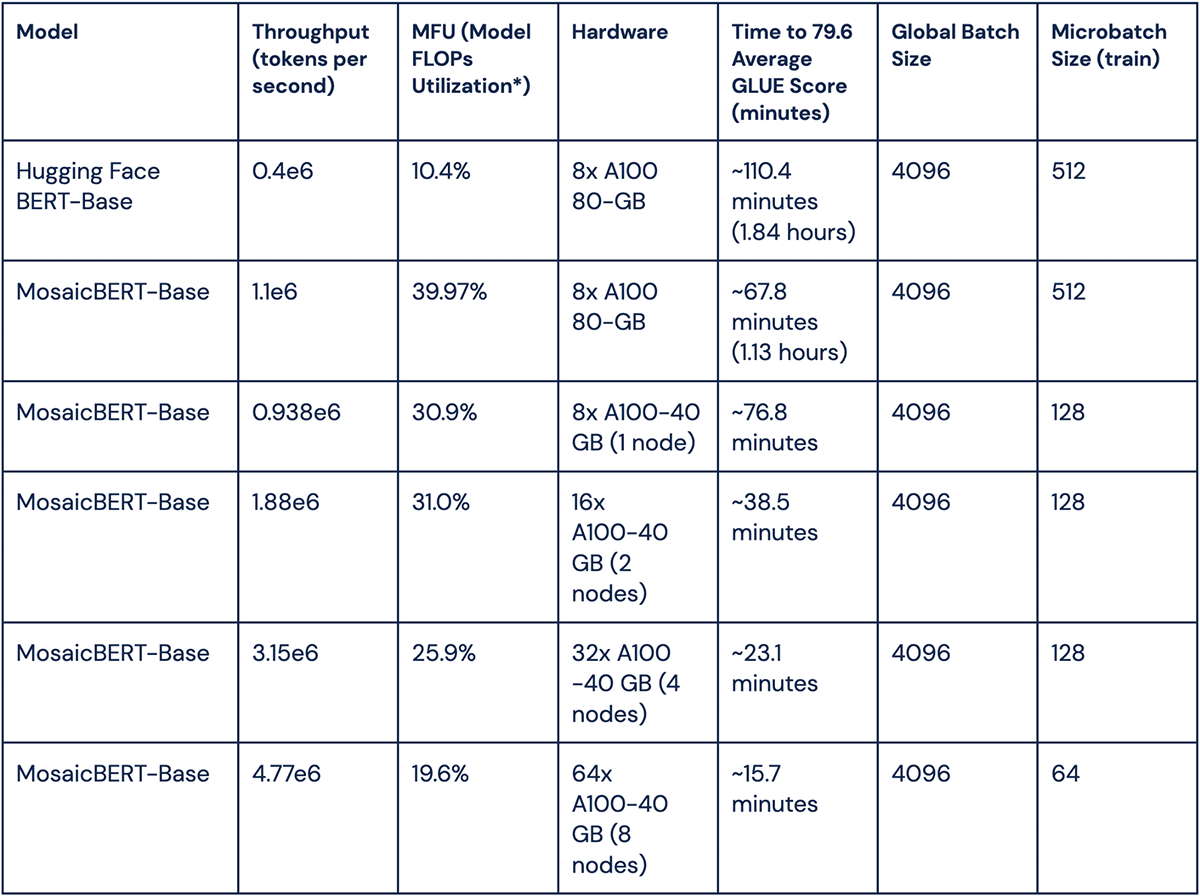
Multinode Scaling of MosaicBERT
With the MosaicML platform, we can easily scale our training runs across multiple nodes. In the following table, we benchmark MosaicBERT-Base throughput (samples per second) scaled across 8, 16, 32 and 64 nodes. We also show that MosaicBERT-Base has higher throughput than the BERT-Base baseline. With 64 nodes, you can train MosaicBERT-Base to an average GLUE score of 79.6 in 15 minutes!
MosaicBERT-Large and Beyond
While BERT-Base is one of the most popular BERT models, BERT-Large comes in a close second. After pushing the efficiency limits on BERT-Base, we were curious whether our architecture and pretraining choices also generalized to larger models.
BERT-Large has 24 repeated transformer blocks (BERT-Base has 12), and as a result consumes much more memory and takes longer to train. We found that MosaicBERT-Large reached an average GLUE score of 83.2 in 15.85 hours, while Hugging Face’s BERT-Large took 23.35 hours. MosaicBERT-Large therefore had a 1.47x speedup over BERT-Large in this training regime.
While MosaicBERT-Base is optimal for a constrained budget, MosaicBERT-Large average GLUE score eventually surpasses MosaicBERT-Base after ~25 hours of training on a 8xA100-80GB node, and reaches an average score of 85.5 in ~60 hours.
In our experiments, the MosaicBERT-Large architecture and pretraining was the same as MosaicBERT-Base, outside of the number of attention heads, number of hidden layers, and intermediate size of the feedforward units.
These results are a first pass; we are also training MosaicBERT models at >1B parameter scale with FSDP, and hope to share our findings soon.
Discussion
Improvements in transformer architecture and GPU hardware have caused the cost of pretraining BERT models to decline precipitously.
The very recent paper “Cramming: Training a Language Model on a Single GPU in One Day” [Geiping and Goldstein 2022] exemplifies this trend. Similar to us, they tweaked the BERT architecture to incorporate FlashAttention and Gated Linear Units (but without increasing the dimensionality of the hidden block). Unlike MosaicBERT, they used scaled sinusoidal positional embeddings [Vaswani et al. 2017] as well as Pre-LayerNorm (applying LayerNorm before the attention and feedforward layers) and did not change the pretraining masking rate. (Note: we did not find that Pre-LayerNorm made a significant difference for MosaicBERT-Base, and therefore chose not to incorporate this.) With this setup, they were able to train their modified BERT-Base to an average GLUE score of 78.6 in 24 hours on a single A6000 GPU (i.e. 24 GPU hours).
While we believe that our training optimization choices for Mosaic BERT go a long way to improve BERT training efficiency, there are still exciting optimizations to pursue. “NarrowBERT” [Li et al. 2023] suggested a clever change to the way encoder blocks are stacked so that computation is not wasted on unmasked tokens. There are likely further modifications that could lead to even faster convergence, such as replacing LayerNorm with RMSNorm [Zhang and Sennrich 2019, Narang et al. 2021].
We have found that approaches such as Knowledge Distillation [Blakeney et al. 2022] and dynamic masking rates can consistently push the Pareto frontier of BERT models during pretraining and finetuning. As the field is learning how to optimize stable model training at the billion parameter scale [Chowdhery et al. 2022, Dehgani et al. 2023], we expect some of these innovations to cycle back to smaller models such as BERT-Base.
Concluding Thoughts
BERT models can be pretrained from scratch to competitive accuracy for around $20 on the MosaicML platform. We built MosaicBERT to enable ML researchers and engineers to pretrain BERT models from scratch on their own data and build better models for their specific domains—without facing time and cost restrictions.
We don’t think the dust has settled, and look forward to pushing the efficiency of widely used models like BERT. In the meantime, join our Community Slack, and sign up for a demo to see how easy it is to train BERT models on our platform. Stay tuned for our future work!.
Thanks to Abhinav Venigalla, Moin Nadeem, Nikhil Sardana, Vlad Ivanchuk, Ishana Shastri, Davis Blalock, and Daya Khudia for their help on improving MosaicBERT, and Jonathan Frankle, Naomi Saphra, Erica Yuen, and Emily Hutson for feedback on this blogpost. *denotes equal contribution. Alex, Jacob and Sam ran experiments, and Alex built the final MosaicBERT architecture, which we almost called AlexBERT.
Appendix
References Relating to Pretraining on Domain-Specific Data
There is mounting evidence that pretraining + finetuning on domain-specific data improves downstream evaluation accuracy, in contrast to just finetuning on domain-specific data. We’ve created a reading list of select research papers that touch on this broader question:
- BERTOverflow: Code and Named Entity Recognition in StackOverflow (Tabassum et al. 2020)
- BioBERT: a pre-trained biomedical language representation model for biomedical text mining (Lee et al. 2019)
- Downstream Datasets Make Surprisingly Good Pretraining Corpora (Krishna et al. 2022)
- Domain-Specific Language Model Pretraining for Biomedical Natural Language Processing (Gu et al. 2021)
- Don't Stop Pretraining: Adapt Language Models to Domains and Tasks (a.k.a TAPT) (Gururangan et al. 2020)
- Foundation Models of Scientific Knowledge for Chemistry: Opportunities, Challenges and Lessons Learned (Horawalavithana et al. 2022)
- Insights into pretraining via Simpler Synthetic Tasks (Wu et al. 2022)
- LinkBERT: Pretraining Language Models with Document Links (Yasunaga et al. 2022)
- MathBERT: A Pre-trained Language Model for General NLP Tasks in Mathematics Education (Shen et al. 2021)
- Pre-train or Annotate? Domain Adaptation with a Constrained Budget (Bai, Ritter, Xu 2021)
- Pre-Training a Language Model Without Human Language (Chiang, Lee 2020)
- Re-train or Train from Scratch? Comparing Pre-training Strategies of BERT in the Medical Domain (Boukkouri et al. 2022)
- SCIBERT: A Pretrained Language Model for Scientific Text (Beltagy, Lo, Cohan 2019)
- WHEN FLUE MEETS FLANG: Benchmarks and Large Pre-trained Language Model for Financial Domain (Shah et al. 2022)
GLUE Benchmark Details
For those who might be hazy on the details of GLUE, we elaborate on the individual benchmarks below:
Large Finetuning Datasets
- MNLI (Multi-Genre Natural Language Inference) [392,702 train, 19,643 test] is a large crowd-sourced entailment classification task [Williams et al., 2018]. The model is given two sentences and has to predict whether the second sentence is entailed by, contradicts, or is neutral with respect to the first one. For example:
Premise: "Buffet and a la carte available."
Hypothesis: "It has a buffet."
Label: 0 (entailment)
- QNLI [104,743 train, 5,463 test] this Stanford Question Answering Dataset consists of question-paragraph pairs drawn from Wikipedia.
- QQP (Quora Question Pairs 2) [363,846 train, 390,965 test]. The task is to determine whether two sentences are semantically equivalent.
Small Finteuning Datasets
- RTE (Recognizing Textual Entailment) [2,490 train, 3,000 test] Given two sentences, the model has to predict whether the second sentence is or is not entailed by the first sentence. Note that in our work we use a checkpoint from the MNLI finetuning to finetune on RTE.
- CoLA (Corpus of Linguistic Acceptability) [8,551 train, 1,063 test] is a benchmark with sentences that are either linguistically acceptable or grammatically incorrect. For example:
"The higher the stakes, the lower his expectations are." Label: 1 (acceptable)
Mickey looked up it." Label: 0 (unacceptable)
- SST-2 (Stanford Sentiment Treebank) [67,349 train, 1,821 test] consists of sentences from movie reviews. The task is to classify the sentiment as either positive or negative.
- MRPC (Microsoft Research Paraphrase Corpus) [3,668 train, 1,725 test] The dataset consists of sentence pairs extracted from online news sources [Dolan & Brockett, 2005]. The task is to classify whether the sentences in the pair are semantically equivalent.
- STSB (Semantic Textual Similarity Benchmark) [5,749 train, 1,379 test] This dataset contains sentence pairs that are given similarity scores from 0 to 5 [Cer et al., 2017].
Note that we excluded finetuning on the 9th GLUE task WNLI (Winograd NLI), as in the original BERT study (it is a very small dataset [634 train, 146 test] with a high number of adversarial examples). Finetuning on RTE, MRPC and STSB starts from a checkpoint already finetuned on MNLI (following the example of Izsak et al. 2021 and other studies). This is done because all the above tasks deal with sentence pairs, and this staged finetuning leads to consistent empirical improvement.
Model FLOPs Utilization (MFU)
As introduced by the PaLM paper [Chowdhery et al. 2022], MFU is defined as:
MFU = (6 * n_parameters * observed_throughput) / (n_gpus * theoretical_peak_throughput)
In the numerator, the number of learnable parameters in the model is multiplied by a factor of 6 to estimate the matmul FLOPs per token seen (2x for the forward pass and 4x for the backward pass). This is then multiplied by the number of tokens seen per second. As a first-order approximation, we exclude the extra FLOPs per token due to dense self-attention.
In the denominator, the theoretical peak throughput is provided in the GPU hardware specs. For A100 GPUs using bfloat16, this theoretical peak throughput is 312 teraFLOPs.
General References
Blakeney et al. 2022 Reduce, Reuse, Recycle: Improving Training Efficiency with Distillation
Chowdhery et al. 2022 PaLM: Scaling Language Modeling with Pathways
Dao et al. 2022 FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness
Dauphin et al. 2016 Language Modeling with Gated Convolutional Networks
Dehgani et al. 2023 Scaling Vision Transformers to 22 Billion Parameters
Devlin et al. 2018 BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
Geiping and Goldstein 2022 Cramming: Training a Language Model on a Single GPU in One Day
Gu et al. 2020 Domain-Specific Language Model Pretraining for Biomedical Natural Language Processing
Hua et al. 2022 Transformer Quality in Linear Time
Izsak et al. 2021 How to Train BERT with an Academic Budget
Li et al. 2023 NarrowBERT: Accelerating Masked Language Model Pretraining and Inference
Liu et al. 2019 RoBERTa: A Robustly Optimized BERT Pretraining Approach
Narang et al. 2021 Transformer Modifications Transfer Across Implementations and Applications?
Press et al. 2021 Train Short, Test Long: Attention with Linear Biases Enables Input Length Extrapolation
Sahn et al. 2019 DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter
Shazeer 2020 GLU Variants Improve Transformer
Vaswani et al. 2017 Attention Is All You Need
Zeng et al. 2022 Boosting Distributed Training Performance of the Unpadded BERT Model
Zhang and Sennrich 2019 Root Mean Square Layer Normalization